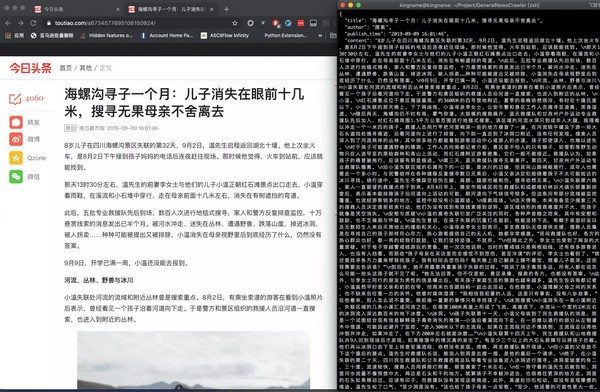
GeneralNewsExtractor(新闻网页正文通用抽取器)是一个基于《基于文本及符号密度的网页正文提取方法》论文用Python实现的正文抽取器,可以用来提取 HTML 中正文的内容、作者、标题。

开发介绍
项目起源
开发这个项目,源自于我在知网发现了一篇关于自动化抽取新闻类网站正文的算法论文――《基于文本及符号密度的网页正文提取方法》)
这篇论文中描述的算法看起来简洁清晰,并且符合逻辑。但由于论文中只讲了算法原理,并没有具体的语言实现,所以我使用 Python 根据论文实现了这个抽取器。并分别使用今日头条、网易新闻、游民星空、观察者网、凤凰网、腾讯新闻、ReadHub、新浪新闻做了测试,发现提取效果非常出色,几乎能够达到100%的准确率。
项目现状
在论文中描述的正文提取基础上,我增加了标题、发布时间和文章作者的自动化探测与提取功能。
目前这个项目是一个非常非常早期的 Demo,发布出来是希望能够尽快得到大家的使用反馈,从而能够更好地有针对性地进行开发。
本项目取名为抽取器,而不是爬虫,是为了规避不必要的风险,因此,本项目的输入是 HTML,输出是一个字典。请自行使用恰当的方法获取目标网站的 HTML。
本项目现在不会,将来也不会提供主动请求网站 HTML 的功能。
怎么下载????
window8兼容不?
楼主你真好!太谢谢你了
这款GeneralNewsExtractor(新闻网页正文通用抽取器)软件很不错啊,最新版本新增的功能简直不要太厉害,以后会不会有更惊喜的功能。
既然这个GeneralNewsExtractor(新闻网页正文通用抽取器)是国产软件,那我就会一直支持下去的
GeneralNewsExtractor(新闻网页正文通用抽取器)非常的好 谁用谁知道 建议下载
QQ多少 我给你传一个
GeneralNewsExtractor(新闻网页正文通用抽取器)我用了很久都没问题,大家就放心的使用吧
以前这个GeneralNewsExtractor(新闻网页正文通用抽取器)大小很小,现在居然都已经2.8MB了
GeneralNewsExtractor(新闻网页正文通用抽取器)挺好用的一款炒股软件软件,挺!!!就是下载好慢啊,赶脚那网速走的好无力